In order to build on previous findings, improve transparency and increase results reproducibility, it is important for researchers to be able to re-use research data. For all these reasons, the notion of publication has been evolving over the last ten years and today includes not only the results, but also the essential research data needed to validate the results.
- Definition of research data
What are research data?
Définition de la Directive de la Direction 4.5 de l’UNIL sur le traitement et gestion des données de recherche
Research data includes in particular, but not exclusively :
– primary data: original data collected or generated for the purpose of carrying out a research project;
– existing data collected or copied for immediate or future use in Projects (in particular administrative or statistical data, digitised contents of collections, data available in databases expressly made available to a community of researchers) – original data or contents are not covered by this directive;
– any new data resulting from the processing (analysis, aggregation, transformation, etc.) of primary data.
For example research data include:
- micro-arrays and sequencing data
- statistical analyses
- experimental results
- audio and video recordings
- life sciences imaging
- medical imaging
- computational-based models and simulations
- Data life cycle and Data Management Plan (DMP)
Data life cycle
It is important to manage your datasets as soon as your research project is starting, as well as ensuring that your research data can be used, shared and re-used effectively by you and other researchers during the whole data life cycle (planning phase, active phase and concluding phase).
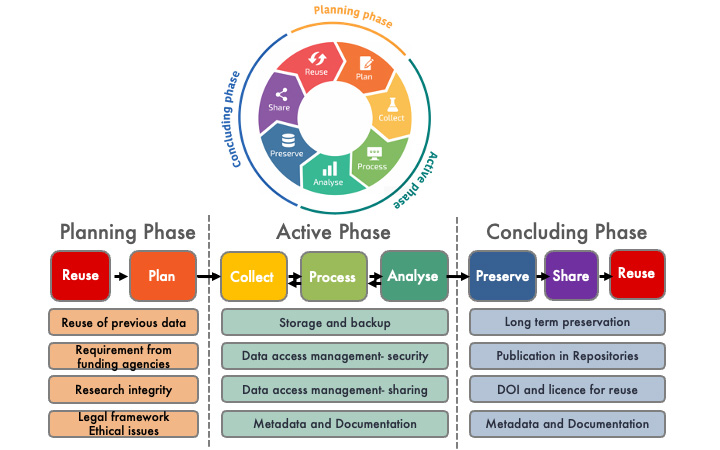
Planning phase
-
- evaluate your data needs
- build a data management plan (DMP). A DMP is an evolving document reporting how the collected or generated research data will be managed during and after a research project. It should describe: the dataset, standards and metadata, data sharing, archiving and preservation.
Active phase
- collect and describe your data
- store and secure (backup plan) your data
- process, visualize and analyse your data
Concluding phase
- publish and share your data
- preserve and archive your data to re-use them in the future
reference: Lebrand Cécile, Rossier Grégoire, & Ioannidis Vassilios. (2023, July 18). FAIR Research Data Management & Data Management Plan. Introduction to FAIR Research Data Management & Data Management Plan, Lausanne, Switzerland. Zenodo. https://doi.org/10.5281/zenodo.8159828
Data Management Plan (DMP)
A DMP is a crucial document in research projects that outlines how data will be managed throughout its entire life cycle. The aim of a DMP is to provide a structured approach to ensure that data is effectively collected, processed, stored, shared, and preserved in a way that promotes data quality, accessibility, and long-term usability. By creating and following a well-structured Data Management Plan, researchers can enhance the quality of their research, facilitate collaboration, comply with funding agency requirements, and ensure the long-term value and accessibility of their data.
Key components of a Data Management Plan typically include:
Data Description: A detailed description of the data to be collected or generated, including its format, structure, and potential volume.
Data Collection: Information about how the data will be collected, including methodologies, instruments, and tools.
Data Documentation: Plans for documenting the data, such as metadata standards, data dictionaries, and annotations, to ensure that others can understand and use the data.
Data Organization and Storage: Details about how the data will be organized, named, and stored during the project. This may involve considerations of file formats, folder structures, and storage locations.
Data Sharing and Access: Plans for making the data accessible to others, which might involve repositories, embargo periods, access controls, and licensing arrangements.
Data Preservation and Archiving: Strategies for preserving the data beyond the project’s completion, including considerations of data formats, storage options, and potential repositories or archives.
Data Security and Ethics: Measures to ensure data security and ethical handling, such as anonymization, encryption, and compliance with relevant regulations or standards.
Roles and Responsibilities: Clearly defined roles and responsibilities for individuals involved in data management, including researchers, collaborators, and data stewards.
Budget and Resources: Allocation of resources, both financial and human, needed for effective data management throughout the project.
Data Disposal: Plans for the secure disposal or retention of data, taking into account legal and ethical considerations.
Data Management Training: Details about any training that will be provided to researchers to ensure they understand and follow proper data management practices.
- FAIR data principles and FAIR data sharing
FAIR data principles
One of the grand challenges of data-intensive science is to facilitate knowledge discovery by assisting humans and machines in their discovery of, access to, integration and analysis of, task-appropriate scientific data and their associated algorithms and workflows. Force11 describes FAIR – a set of guiding principles to make data Findable, Accessible, Interoperable, and Reusable. The term FAIR was launched at a Lorentz workshop in 2014, the resulting FAIR principles were published in 2016 (link).
To be Findable:
F1. (meta)data are assigned a globally unique and eternally persistent identifier.
F2. data are described with rich metadata.
F3. (meta)data are registered or indexed in a searchable resource.
F4. metadata specify the data identifier.
To be Accessible:
A1 (meta)data are retrievable by their identifier using a standardized communications protocol.
A1.1 the protocol is open, free, and universally implementable.
A1.2 the protocol allows for an authentication and authorization procedure, where necessary.
A2 metadata are accessible, even when the data are no longer available.
To be Interoperable:
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles.
I3. (meta)data include qualified references to other (meta)data.
To be Re-usable:
R1. (meta)data have a plurality of accurate and relevant attributes.
R1.1. (meta)data are released with a clear and accessible data usage license.
R1.2. (meta)data are associated with their provenance.
R1.3. (meta)data meet domain-relevant community standards.
FAIR Data Sharing
Research data and metadata are made available in a format that adheres to standards, making them both human and machine-readable, in line with principles of good data governance and management, following FAIR principles (Findable, Accessible, Interoperable, and Reusable). It’s important to note that FAIR does not necessarily imply open accessibility, and sharing can occur in restricted or contractual forms if needed. However, metadata should be made as openly available as possible.
SNSF Explanation of the FAIR Data Principles (PDF) (link)
Wilkinson et al. (2016), The FAIR Guiding Principles for scientific data management and stewardship, Scientific Data 3, doi:10.1038/sdata.2016.18 (link)
- Personal data and Sensitive Data
Research data confidentiality
Personal data
Definition in Switzerland: all information relating to an identified or identifiable person »
LOI 235.1, art. 3. Federal Act on Data Protection
Definition in the canton de Vaud: « Donnée personnelle, toute information qui se rapporte à une personne identifiée ou identifiable »
LOI 172.65 sur la protection des données personnelles (LPrD)
They must also adhere to the Federal Act on Research involving Human Beings, created to protect the dignity, privacy and health of human beings involved in research.
Data concerning humans made publicly available must remain totally confidential and be anonymized. Researchers should include a provision for data sharing in the informed consent.
Sensitive data
Definition in Switzerland:
all information relating to an identified or identifiable person » on:
- religious, ideological, political or trade union-related views or activities,
- health, the intimate sphere or the racial origin,
- social security measures,
- administrative or criminal proceedings and sanctions;
LOI 235.1, art. 3. Federal Act on Data Protection (FADP)
Definition dans le canton de Vaud:
Donnée sensible, toute donnée personnelle se rapportant:
- aux opinions ou activités religieuses, philosophiques, politiques ou syndicales, ainsi qu’à une origine ethnique – à la sphère intime de la personne, en particulier à son état psychique, mental ou physique
- aux mesures et aides individuelles découlant des législations sociales
- aux poursuites ou sanctions pénales et administratives.
LOI 172.65 sur la protection des données personnelles (LPrD)
- Source of information
Data Stewardship Services
Our Data Stewardship service at BiUM closely collaborates with the Service des ressources informationnelles et archives (UNIRIS), which coordinates the data steward network of UNIL (link).
The mission of our service in data stewardship is to establish a cross-functional service aimed at all researchers within FBM UNIL and CHUV, providing them with the skills and tools necessary to produce and manage data in accordance with international FAIR standards and those required by the FNS, for the purpose of sharing and long-term preservation. This contributes to the transparency, reproducibility, and advancement of scientific research.
Our data stewardship service provides comprehensive and tailored support to FBM UNIL-CHUV researchers, helping them manage, share, and preserve their research data effectively and in accordance with best practices and policies.
- Data Management Plan (DMP) Preparation: our service assists researchers in creating effective DMPs for SNFS and European grant applications as well as for data storage purposes. This helps researchers outline how they will collect, manage, and share their data throughout the research process.
- Metadata Standards and File Formats: our service is knowledgeable about metadata standards for datasets and file formats for long-term storage and re-use. This helps researchers organize their data effectively for effective sharing and future use
- FAIR Data Compatibility: our service guides researchers on making their data FAIR (Findable, Accessible, Interoperable, Reusable) compatible. This involves ensuring that metadata is comprehensive and standardized, using open formats and standards, and enhancing data accessibility.
- Open Research Data Sharing: our unit actively supports researchers in sharing their data openly on selected FAIR repositories. This helps increase the visibility of their work within the research community. Regarding Open Research Data (ORD), our guidance on preparing and documenting datasets has facilitated the sharing of over 80 FBM-UNIL and CHUV datasets on the Zenodo repository within the FBM community space (link).
- Identifying Suitable Repositories for Open Data: our service assists researchers in finding appropriate FAIR data repositories that align with the requirements of funding agencies and journals. This ensures that research data can be published and accessed according to established policies.
- Identifying Suitable catalogues for restricted-Access Data: For research sensitive data that cannot be shared openly, we offer guidance in collaboration with the CHUV IT (DSI) service on making datasets visible by publishing metadata describing the data’s characteristics using the CHUV Horus data catalogue. This allows other researchers to understand the dataset that has been published and request access if necessary, following proper legal procedures.
- Data Copyright and Licensing: We assist researchers in understanding data copyright, licensing, and self-archiving rules. This ensures that researchers are aware of their rights and responsibilities when sharing their data.
- Data preservation: Since 2022, our service, in partnership with UNIRIS and Computing and Research Support Division of UNIL (DCSR), has been actively engaged in the implementation of Long-Term Storage (LTS) for FBM-UNIL research data (link). This initiative is of crucial importance in the face of the exponential growth in data storage costs generated by research.
Research Data Management and DMP tools
Since 2016, our service has played a central role in preparing Data Management Plans (DMPs) for the Swiss National Science Foundation (FNS) across the entire FBM UNIL and CHUV. We have contributed to the deployment of interactive and facilitative tools such as the “DMP Online” with UNIRIS for DMP creation. Our service provides specific DMP templates tailored to biomedical biology for the FBM-UNIL and clinical settings for the CHUV, along with a review service.
- DMP Online tool for FNS funding
UNIL is making available an interactive online tool for writing a Data Management Plan (DMP) in a collaborative way and to request a review from our service.
The BiUM templates for FBM UNIL- CHUV are aiming to help you generate Data Management Plans for SNSF funded projects. A web form composed of four sections guides the user through the definition of the requirements for the management of your project data. The produced document is compliant with the SNSF instructions for DMP creation and consists of generic paragraphs corresponding to the user’s inputs. The produced document structure follows the structure of the SNSF DMP questionnaire.
Two DMP templates in English for SNF funding applications are available for UNIL and CHUV researchers of the Faculty of Biology and Medicine:
- FBM UNIL DMP template from the BiUM for SNSF funding
- FBM CHUV DMP template from the BiUM for SNSF funding
To use the tool and access the DMP templates generated by the BiUM and available for UNIL and CHUV researchers please comply with our help page recommendation.
- Research Data Management tool: Data Stewardship Wizard (DSW)
The Data Stewardship wizard (DSW) tool developed and maintained by the European Network ELIXIR-Converge, aims to enhance data management practices and promote openness in research. The tool provides researchers with a comprehensive platform to manage their research data effectively.
We plan the future deployment of DSW tool in collaboration with the SIB/Vital IT , UNIRIS (link) and the Computing and Research Support Division of UNIL (division calcul et soutien à la recherche -DCSR) to assist researchers at FBM UNIL – CHUV in managing their research data according to high standards and evaluating their adherence to FAIR principles. This collaborative effort involves direct partnering with experts like Dr. V. Ioannidis (Lead Computational Biologist at SIB/Vital-IT group).
This customization involves the creation of a life-science model and a biomedical knowledge model within the Data Stewardship Wizard (DSW) framework adapted to Swiss and FBM UNIL-CHUV researchers. Our BiUM trainings using the DSW tool as a basis provide researchers at FBM UNIL-CHUV with a powerful data management solution that supports FAIR principles and openness standards. It assists researchers in effectively organizing, documenting, and assessing their research data, contributing to transparent and reproducible research practices within the biomedical field.
Here are some key points about the tool and its features:
- User-Friendly Interface: The tool offers an ergonomic and user-friendly interface. This includes features such as nested questions that dynamically appear based on the user’s responses.
- Life science and biomedical-Specific Standards: The tool offers lists of file and metadata standards specific to the life-science and biomedical field. These standards are curated and maintained by relevant communities, ensuring that researchers follow best practices for data formatting and documentation within their domain.
- Integration of FBM UNIL-CHUV Data and Standards: The tool integrates in addition data and standards specific to FBM UNIL-CHUV. It takes into account data produced by various research groups and data acquisition and analysis FBM platforms. The tool also incorporates FAIR clinical data generated by the Informatics (DSI) unit as part of Swiss Personalized Health Network (SPHN) projects. This ensures that research data contributes to the larger ecosystem of data management and interoperability
- Biomedical Knowledge Model: The tool’s design incorporates a specialized biomedical knowledge model that aligns with the research focus and requirements of FBM UNIL and CHUV.
- FAIR and Openness Assessment: Researchers using the tool can assess the degree to which their data align with the FAIR principles (Findable, Accessible, Interoperable, Reusable) and openness standards.
- Collaborative Editing: The tool supports advanced collaborative editing, allowing multiple researchers to work together on the same data management plan.
- ELIXIR Involvement: The fact that the tool is developed and maintained by the European Network ELIXIR adds a level of credibility and expertise. ELIXIR is known for its dedication to advancing data management and interoperability in the life sciences.
- BiUM Data Management tool box
Our publication management service is providing a BiUM Data Management tool box for preparing a SNFS Data Management Plan, for long term storage and Open Research Data.
This toolbox consists of :
• FBM CHUV and UNIL DMP tools and templates for SNFS;
• Lists of adapted data repositories for publishing research data;
• Metadata standards for datasets;
• Models of readme files;
• File formats for long term datasets storage and re-use;
• Data licenses to protect your copyrigths.
Workshops on FAIR Research Data Management and Data Management Plan (DMP)
Since 2016, the commitment of our data stewardship service to research data management issues has materialized through over 279 applied presentations and workshops. These workshops cover topics such as DMP writing, Open Research Data (ORD), and Long-Term Storage (LTS), targeting a wide audience including doctoral students (link), post-doctoral researchers, and group leaders (link) from research groups at FBM UNIL-CHUV. Recognizing that the basic level of knowledge acquired by researchers must now be supplemented with deeper understanding, we have been offering advanced workshops on FAIR data management in biomedical sciences for the past year. These workshops are developed by our service in collaboration with SIB/Vital-IT as part of the European ELIXIR network (link).
- DMP training for FBM UNIL-CHUV researchers
Data Management Plan (DMP) accompanying a research project grant application from the SNFS
Responsable and teacher: Cécile Lebrand, PhD
Content:
This workshop in English is a practical training to help researchers from the FBM UNIL and CHUV to fill their Data Management Plan (DMP), a compulsory evolutive document required by the SNSF when applying for a subside for a research project. Link
During this training, the participants will be help for completing the major DMP fields of their grant application on mySNF using the UNIL DMP online tool:
1. Data collection and documentation
2. Ethical, legal and security issues
3. Storage and preservation of data
4. Sharing and re-use of data
This training is open and free to all FBM UNIL and CHUV researchers applying to the SNSF for a basic or clinical research project.
This teaching is also offered in French (link)
To plan a DMP training please contact us by e-mail: Cecile.Lebrand@chuv.ch
- FAIR/Open Research Data training for FBM UNIL-CHUV researchers
Practical workshops: Publishing research data sets to accompany publications – improving the visibility and reproducibility of your work.
Responsable and trainer: Cécile Lebrand, PhD
Open Research Data – Publishing research data sets to accompany publications
Content:
- During this workshop, researchers will be informed about the Open Data guidelines currently being applied by publishing houses and funding agencies.
- They will learn about the issues involved in sharing the data associated with publications and the resulting benefits for them and for the scientific community in general.
- Biomedical researchers and clinicians will learn how to bring their data into line with good practice in research data management and the FAIR principles.
- They will also learn in practical terms about the importance of metadata, i.e. the information that must accompany their research data so that it can be understood and re-used, as well as the different formats recommended for sharing and long-term access to each type of data they create.
- They will also be introduced to the use of Creative Commons licences to protect their copyright
- Through practical exercises, researchers will be introduced to the use of data repository such as Zenodo, in order to deposit their datasets accompanying their publications, as well as to search for and download data from colleagues that could be useful to them.
This training is open and free to all FBM UNIL and CHUV researchers.
This teaching is also offered in French (link)
To plan a FAIR data sharing/ORD training please contact us by e-mail: Cecile.Lebrand@chuv.ch
- FBM Doctoral School Courses on FAIR Research Data Management
The course FAIR Research Data Management in biomedical and clinical research – ED 26/Série 4 (Link)
Responsable: Cécile Lebrand, PhD
Teachers: C. Lebrand, J. Zbinden
Language: English
Credits: 0.25
Objectif
At the end of the course participant should be able to put in place a DMP and to share their published data in Open Access, making possible to:
-respond to the requirements of the journals and financing agencies which require FAIR standards and transparent practices in research
-anticipate in detail the management of research data using FAIR standards, specifying how this data is going to be analysed, organised, stored, secured and shared.
-how to use the tool DMPonline UNIL , an interactive tool designed to help in the (co-)writing, editing and sharing of DMPs.
Content
During the first part of this workshop, participants will be taught best FAIR practices in data management and how to collect, describe, store, secure and archive research data. they will be introduced to the need for a Data Management Plan (DMP) preparation. The second half of the workshop will be dedicated to practical on Data management, where participants will learn how to fill a DMP corresponding to their thesis research project and how to share their published data on adapted repository.
- SIB/VitalIT courses on FAIR Research Data Management and Data Management Plan
This series of courses, given by our service in collaboration with SIB/Vital-IT will provide Swiss researchers with the knowledge and the tools to generate robust data and excellent quality studies that follow the FAIR principles. This courses will also provide you with effective support to build high quality DMP complying with the guidelines established by funding agencies.
Module 1: Introduction to FAIR Research Data Management & Data Management Plan (link)
This two-day course is designed to equip post-graduate students and researchers with the skills needed to effectively manage research data and prepare Data Management Plans (DMPs).
On the first day, participants will learn about research reproducibility and the importance of DMP preparation. Best practices in FAIR Research Data Management (RDM) will be covered, focusing on data collection and documentation. The afternoon session will delve into additional aspects of RDM, including ethics, legal considerations, data preservation, and sharing, along with an overview of FAIR principles.
The second day will focus on using the “Data Stewardship Wizard” tool to create personalized DMPs. Participants will also have the opportunity to present and discuss their draft DMPs with the group.
By the end of the course, participants will understand DMP requirements, be able to manage research data effectively following best practices, and grasp the FAIR guiding principles and Open Data foundation.
Module 2: Make your Research Data Fair (link)
For more information concerning upcoming training course:
Tools and services for Long Term Storage (LTS) /archiving of your data at UNIL
Archiving your data at UNIL
Through the process of data life cycle management, our team at BiUM is providing information, advice and help to FBM UNIL researchers for long term storage and preservation of their data for free at the DCSR UNIL.
We can provide you with guidance on how to prepare a Readme file and reorganize your data in order to preserve your work.
- Informing and guiding you through the process of reorganizing and describing your research data in the form of explanatory documents called “readme file”.
- Final validation of your readme file before data migration from the DCRS NAS to the LTS platform.
Additional information:
In French: https://www.bium.ch/processus-dhebergement-donnees-de-recherche-stockage-a-long-terme/
In English: https://www.bium.ch/en/process-of-hosting-search-data-for-long-term-storage/
Tool: readme file
A readme file serves as a documentation resource that offers crucial details about a dataset. Its primary purpose is to ensure accurate interpretation and understanding of the data, both for your future reference and for others who may access or collaborate on the data, including when sharing or publishing it. By providing clear and comprehensive information, a readme file enhances the usability, reproducibility, and transparency of the data, contributing to effective data management and research practices.
Key elements that a thorough readme file should contain:
- File Descriptions and Relationships: Provide a succinct description of each data file included, highlighting what specific data it contains. If relevant, describe how these data files relate to tables, figures, or sections within the associated publication. This context helps users understand the purpose and relevance of each data file.
- Tabular Data Details: For tabular data, elucidate the meaning of column headings and row labels. Define any data codes used, including those for missing data, and specify the measurement units applied. This ensures that users can accurately interpret and work with the data.
- Data Processing Steps: Detail any data processing steps that may affect the interpretation of results, especially if these steps are not already explained in the accompanying publication. This transparency aids users in understanding the transformations applied to the data and their potential impact on analysis.
- Associated Datasets: If certain datasets are stored elsewhere but are associated with the data in question, provide a clear description of these datasets and where they can be accessed. This helps users locate related resources and fosters a more comprehensive understanding of the data context.
- Contact Information: Include clear contact information for inquiries or questions related to the data. This ensures that users have a direct point of contact if they need clarification, assistance, or further information about the dataset.
Reference
Dryad recommendations
Recommendation from Cornell University
Readme file template for LTS at UNIL
Template: LongTermStorage_Data_Description_EN
There’s a plan to deploy a user-friendly and automated methodology for generating readme files fro Big Datasets, developed by Professor Aleksandar Vještica at CIG. This innovative approach will empower researchers to adeptly convey crucial details about their datasets through these readme documents. This advancement promises to further enhance data communication and understanding within the FBM UNIL research community.
Journal and funding agencies Open Data policies
- What are the advantages for researchers and the scientific community to make datasets freely accessible and reusable?
- What are the journal guidelines concerning reporting standards and data sharing?
- What are the funding agencies policies concerning data sharing?
Research funding agencies, publishers and institutions increasingly require shared standards for open practices in research. The list below includes top funders and journal guidelines.
We can provide you with guidance on how to prepare a Data Management Plan and how share your data through journal publications and selected repositories to meet founding agencies and journal requirements. Trainings concerning these aspects are also provided by our service on regular basis (check our calendar).
- Irreproducibility of published studies in biomedical research
Irreproducibility of published studies in preclinical and clinical research.
Recent studies have shown that worldwide, between 51% to 89% of published preclinical and clinical research is not reproducible, with consequent losses estimated around $100 billions/year in biomedical reerch (Chalmers et al., 2009; Freedman et al., 2015; Begley and Ioannidis, 2015). In particular, these studies have made clear that the research data associated with a publication are fundamental to validate the published analyses and results. Preclinical studies are essential, since they are a potential basis for the discovery of new drugs and therapies, as well as for the use of specific biomarkers in clinical analyses (Begley and Ellis, 2012; Freedman et al., 2015; Begley and Ioannidis, 2015). The low reproducibility rate of research carried out in life sciences is therefore alarming since it causes delays and major costs in therapeutic developments.
This irreproducibility is not only exclusive to preclinical studies but is observed all across the biomedical research spectrum. Indeed, similar problems have been identified for observational research where zero of 52 predictions from observational studies were confirmed in randomized clinical trials (Begley and Ioannidis, 2015).
Many causes contribute to this lack of reproducibility in life science studies. For example, researchers often do not conduct their preclinical experiments in a blind manner and therefore tend to identify the results they anticipated (Howells al., 2014; Begley and Ioannidis, 2015). This confirmation bias in scientific research is inevitable and even the best scientists are inclined to unconsciously find results or interpretations that fit their preconceived ideas and theories. A series of recurring problems have also been highlighted, including the lack of sufficient repetition of the number of experiments, the absence of adequate controls, the lack of reagents validation, lack of transparency and standarts while reporting research results and not using appropriate statistical tests (Begley and Ellis, 2012; Howells al., 2014; Begley and Ioannidis, 2015, Holman et al., 2016). In addition to this, researchers often choose the best experience rather than all, and negative results are rarely published. This absence of standards and best practices has led not only to the lack of reproducibility of individual experiences but also to the fact that the main conclusions of the articles are often not correctly documented.
The irreproducibility of preclinical research is attributed to a lack of both rigor and follow-up of good experimental practices at various stages of the research cycle: i) biological reagents and reference materials, ii) improper preliminary studies design, iii) lack of rigor in data analysis and in reporting research results and iv) random laboratory protocols (Freedman et al., 2015).
Sources of information
- Begley, CG, and Ellis L L. “Drug development: Raise standards for preclinical cancer research” Nature. 2012 Mar 28;483(7391):531-3.
- Begley, C G, and Ioannidis, J. PA. “Reproducibility in science improving the standard for basic and preclinical research.” Circulation research. 2015; 116.1: 116-126.
- Chalmers I, Glasziou P. Avoidable Waste in the Production and Reporting of Research Evidence. Lancet. 2009; 374(9683): 86–89.
- Freedman LP, Cockburn IM, Simcoe TS. The Economics of Reproducibility in Preclinical Research. PLoS Biol. 2015;13(6): e1002165.
- Holman C, Piper S K, Grittner U, Diamantaras A A , Kimmelman J, Siegerink B, and Dirnagl U “Where Have All the Rodents Gone? The Effects of Attrition in Experimental Research on Cancer and Stroke” PLoS Biol. 2016 Jan 4;14(1):e1002331.
- Howells, D. W., Sena E.S., and Macleod, M.R. Bringing rigour to translational medicine. Nat Rev Neurol. 2014 Jan;10(1):37-43.
- Iqbal SA, Wallach JD, Khoury MJ, Schully SD, Ioannidis JPA.”Reproducible Research Practices and Transparency across the Biomedical Literature.” PLoS Biol. 2016. 14(1): e1002333.
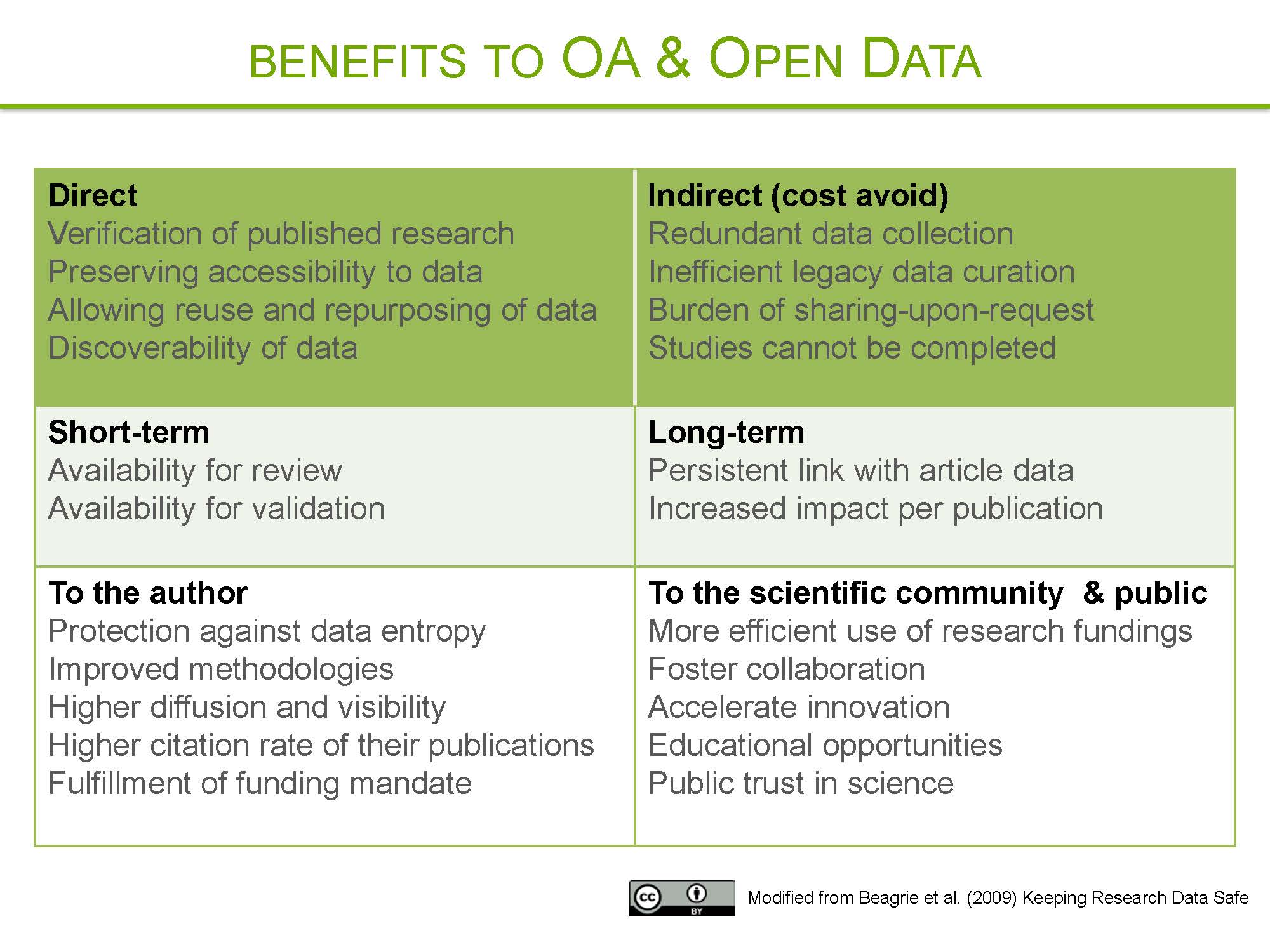
- Benefits to data sharing
Benefits to data sharing
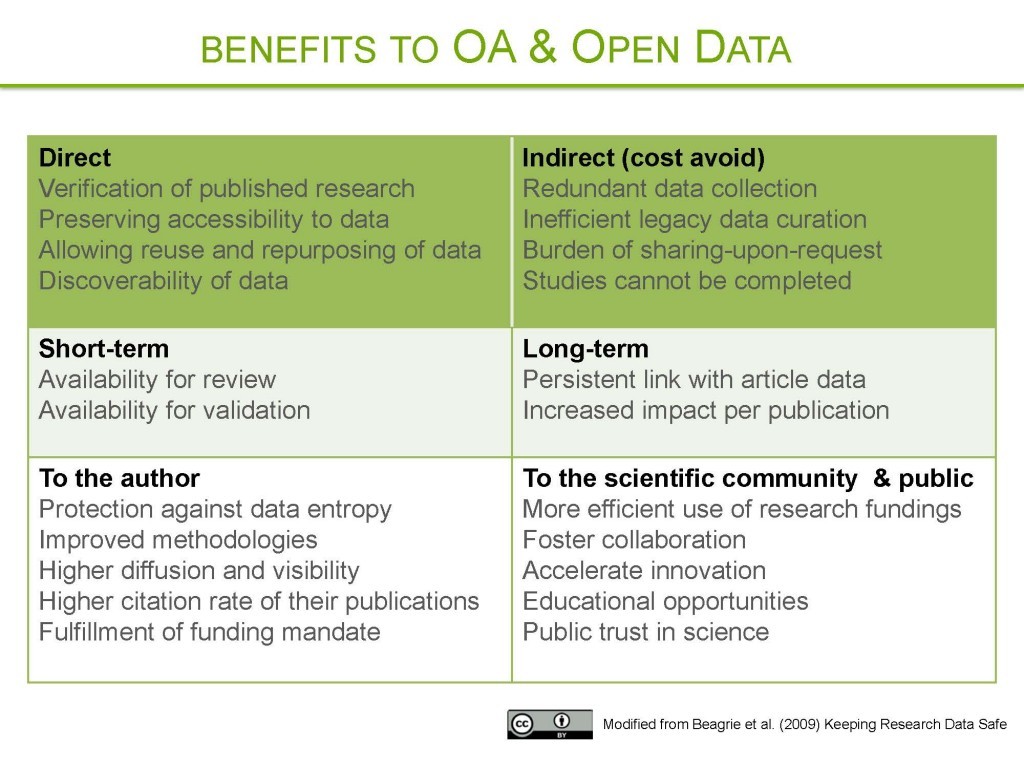
Data reuse and citation advantage: Citations are higher for articles that shared data (ex : gene microarray) versus those that do not, independently of the journal IF, the date of publication, and author country of origin (Piwowar H et al. (2007) PLoS ONE).
Point of view: How open science helps researchers succeed (McKiernan et al. (2016) eLife)
- Open data policies from publishers
Policies for open research data from publishers
Too often, publication requirements discourage transparency, openness, and reproducible science. For example, both null and significant results must be made available to ascertain with accuracy the evidence based of a phenomenon. However, as of today, null results are only rarely published and remain inaccessible to knowledge. In addition, to maintain high standards of research reproducibility, and to promote the reuse of new findings, major research data associated with a publication should be made OA according to reporting standards. For this reason, data sharing policies are now often introduced in the instructions for authors by publishers. This requirement is due to the fact that research data are fundamental to validate the analyses and results published in the research article. From this point of view research data are considered as a crucial part of the publication.
In November 2014, The Transparency and Openness Promotion (TOP) Committee met at the Center for Open Science in USA, to address the question of journals’ procedures and policies for publication. The committee comprised researchers, journal editors and funding agency representatives. By developing shared standards for open practices across journals, they wished to change the current research incentive system to drive researchers’ attitude toward more openness. They created eight standards in the TOP guidelines which invite scientific communication to move toward greater openness. The TOP guidelines respect barriers limitation to openness by accepting exceptions to sharing due to ethical issues and intellectual property issues or availability of necessary resources. The guidelines have been published in Science in B. A. Nosek et al. Science 2015;348:1422-1425 and are available at at http://cos.io/top, along with a list of 510 top leading journals and 49 organizations that have already agreed to this guideline (September 14 2015).
Eight standards and three levels of the TOP guidelines provides a summary of the guidelines. “The three levels of the TOP guidelines are increasingly stringent for each standard. Level 0 offers a comparison that does not meet the standard. Two standards (Citation and replication standards) reward researchers for the time and effort they have spent engaging in open practices. Four standards describe what openness means across the scientific process so that research can be reproduced and evaluated. Finally, two standards address the values resulting from preregistration.” Making transparent the distinction between confirmatory and exploratory methods can enhance reproducibility. It is specified that the standard “Design and Analysis Transparency” should maximize transparency about the research process and minimize potential for incomplete reporting of the methodology. This standard is Discipline-specific and the journals should identify if existing reporting guidelines apply (standards available for many research applications from http://www.equator-network.org/) and select the guidelines that are most relevant.
- 02.2015: NIH adopted the Principles and Guidelines for Reporting Preclinical Research
- 11.2014: Nature published Journals unite for reproducibility
- 12.2014 : Science published Journals unite for reproducibility
- 06.2014: the US National Institute of Neurological Disorders and Stroke organized a meeting with major stakeholders in order to discuss how to improve the methodological reporting of animal studies in funding applications and publications. The main workshop recommendation Principles and Guidelines in Reporting Preclinical Research is that at a minimum “studies should report on sample-size estimation, whether and how animals were randomized, whether investigators were blind to the treatment, and the handling of data. Journals should recommend the deposit of data in open access repositories where available and link data bidirectionally to the published paper. Journals should also strongly encourage, as appropriate, that all materials used in the experiment be shared with those who wish to replicate the experiment.”
- 06.2010: PLoS Biology: Improving Bioscience Research Reporting: The ARRIVE Guidelines for Reporting Animal Research.“The Animal Research: Reporting of In Vivo Experiments (ARRIVE) guidelines were introduced to help improve reporting standards in 2010. To maximise their utility, the ARRIVE guidelines have been prepared in consultation with scientists, statisticians, journal editors, and research funders. They were published in PLoS Biology and endorsed by funding agencies and publishers and their journals, including PLoS, Nature research journals, and other top-tier journals”.
- DMP and Open data policies from SNSF
Funding agencies (SNSF and H2020) and institutions (UNIL/CHUV) also strongly encourage authors to provide OA to research data, unless there are strong reasons to restrict access, for example in the case of medical or commercial data. Data privacy for sensitive information related to personal and private information needs to be handled carefully, especially in the biomedical field (see our section on confidentiality and intellectual property). Indeed, the divulgation and open-access of sensitive data implies the explicit consent of the individuals as well as privacy protection through data anonymization. In addition, in case of commercial and patenting issues access to research data may have to be restricted and protected.
SNSF policy on DMP and Open Research Data
Research data should be freely accessible to everyone – for scientists as well as for the general public.
The SNSF agrees with this principle and will introduce new requirements in its project funding scheme as of October 2017. Researchers will have to include a data management plan (DMP) in their funding application. At the same time, the SNSF expects that data generated by funded projects will be publicly accessible in non-commercial and FAIR digital databases provided there are no legal, ethical, copyright or other issues.
For more detailed information regarding the implementation of the SNSF policy on Open Research Data (ORD), please refer to this webpage.
We can provide you with guidance on how to prepare a Data Management Plan and how share your data selected repositories to meet SNSF requirements. Trainings concerning these aspects are provided by our service on regular basis (check our calendar).
SNSF guidelines for researchers concerning the Data Management Plans (DMPs)
- Guidelines
- Content of the DMP
- Use the “DMP online tool” adapted for FBM-UNIL/CHUV researchers to make your own DMP template.
- Contact Cecile.lebrand@chuv.ch to get access to our model on how to fill the Data Management Plan provided by the SNFS while applying for a funding.
SNSF policy on Open Research Data
- “Research data are the evidence that underpins the answer to the research question, and can be used to validate findings regardless of its form (e.g. print, digital, or physical).”
Concordat on Open Research Data, published on 28 July 2016
- The SNSF values research data sharing as a fundamental contribution to the impact, transparency and reproducibility of scientific research. In addition to being carefully curated and stored, the SNSF believes research data should be shared as openly as possible.
- The SNSF therefore expects all its funded researchers
- to store the research data they have worked on and produced during the course of their research work, to share these data with other researchers, unless they are bound by legal, ethical, copyright, confidentiality or other clauses, and
to deposit their data and metadata onto existing public repositories in formats that anyone can find, access and reuse without restriction.
- Research data is collected, observed or generated factual material that is commonly accepted in the scientific community as necessary to document and validate research findings.
SNSF regulations
The regulations related to the SNSF policy on Open Research Data can be found in the Funding Regulations and in the General Implementation Regulations.
SNSF conformed data repositories
Finding the “perfect” repository providing all necessary features to host FAIR data is challenging. To make the transition towards FAIR research data easier, the SNSF decided to fix a set of minimal criteria that repositories have to fulfil to conform with the FAIR data principles.
Costs for granting access to research data (Open Research Data) – Article 28 paragraph 2 letter c of the Funding Regulations:
The costs of enabling access to research data that was collected, observed or generated under an SNSF grant are eligible if the following requirements are met: a. The research data is deposited in recognised scientific, digital data archives (data repositories) that meet the FAIR6 principles and do not serve any commercial purpose. b. the costs are specifically related to the preparation of research data in view of its archiving, and to the archiving itself in data repositories pursuant to letter a
- Open data policies from H2020
Horizon 2020: Open Data Policy
Since January 2017, all researchers submitting a project proposal in the context of Horizon 2020 have automatically been included in the Open Data pilot.
- Open data policies and repositories list
Where to publish your datasets: Data repositories
- Where should researchers working at FBM/CHUV deposit their datasets accompanying their publication?
- Which kind of documents can be self-archived?
- Which document format to use for long-term storage?
- What are the copyright and licence legal aspects for datasets?
- When can Open Access to a dataset underlying an article be provided?
Services
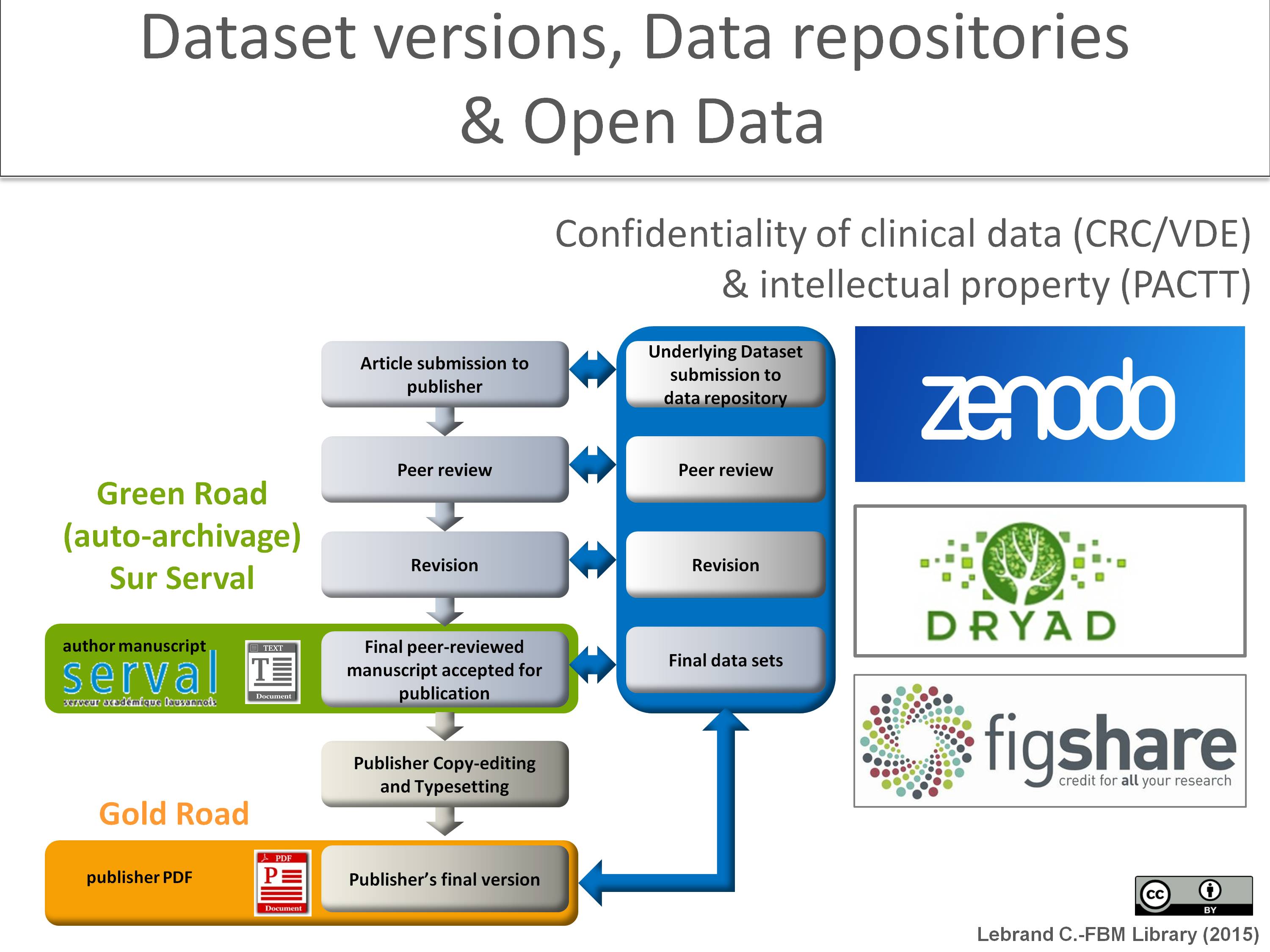
The BiUM publication management unit helps all FBM/CHUV researchers address reporting standards and data sharing policies requirements. Our unit strongly recommends to FBM/CHUV researchers to make their supplementary files and key datasets (life science and medical images, audio-video recordings, blots, ….) accompanying the publication openly available on the appropriate data repository. The preferred way to share large data sets is via public repositories for specific data sets or unstructured public repository like H2020 data repository Zenodo-FBM/CHUV community.
FBM/CHUV researchers who would like to deposit and give free Open Access to the unstructured data underlying their publication via Zenodo-FBM/CHUV community , Dryad or figshare can contact the BiUM publication management unit. We will provide you with guidance on how to share your data through data repository to increase the visibility of your work. Our unit is well aware of metadata standards for datasets, file formats for long term datasets storage and re-use, data copyright, licenses and self-archiving rules and will help you in addressing these issues. Trainings concerning these aspects are also provided by our service on regular basis (check our calendar).
Data privacy for sensitive information related to personal and private information needs to be handled carefully, especially in the biomedical field (see our section on confidentiality and intellectual property). Indeed, the divulgation and open-access of sensitive data implies the explicit consent of the individuals as well as privacy protection through data anonymization. In addition, in case of commercial and patenting issues access to research data may have to be restricted and protected. Our service is not responsible for the proper anonymization of datasets before deposit and request reserchers to consult the services in charge of these aspects at UNIL/CHUV.
Authors may be invited by the publisher to submit key research data that support the figures and tables in long term access formats together with appropriate metadata to data repositories while submitting the article to the journal or after manuscript acceptance. During the review process, researchers can post data files with restricted access and have the ability to share their results only with journal editors and reviewers. Data Repositories will assign a DOI to make research data uniquely citeable. Linking the research dataset directly to the publication by citing it in the reference list will ensure that the dataset is found in the future. Upon publication acceptance, open access and sharing of the data accompanying the publication will be subject to the approval by the depositor of the original file.
For discipline data repositories consult the list provide by PLoS journals or Scientific Data journal. For exemple for genomic, proteomic and metabolomic datasets, authors should use domain-specific public repositories (contact VITAL-IT for further information).
Tool
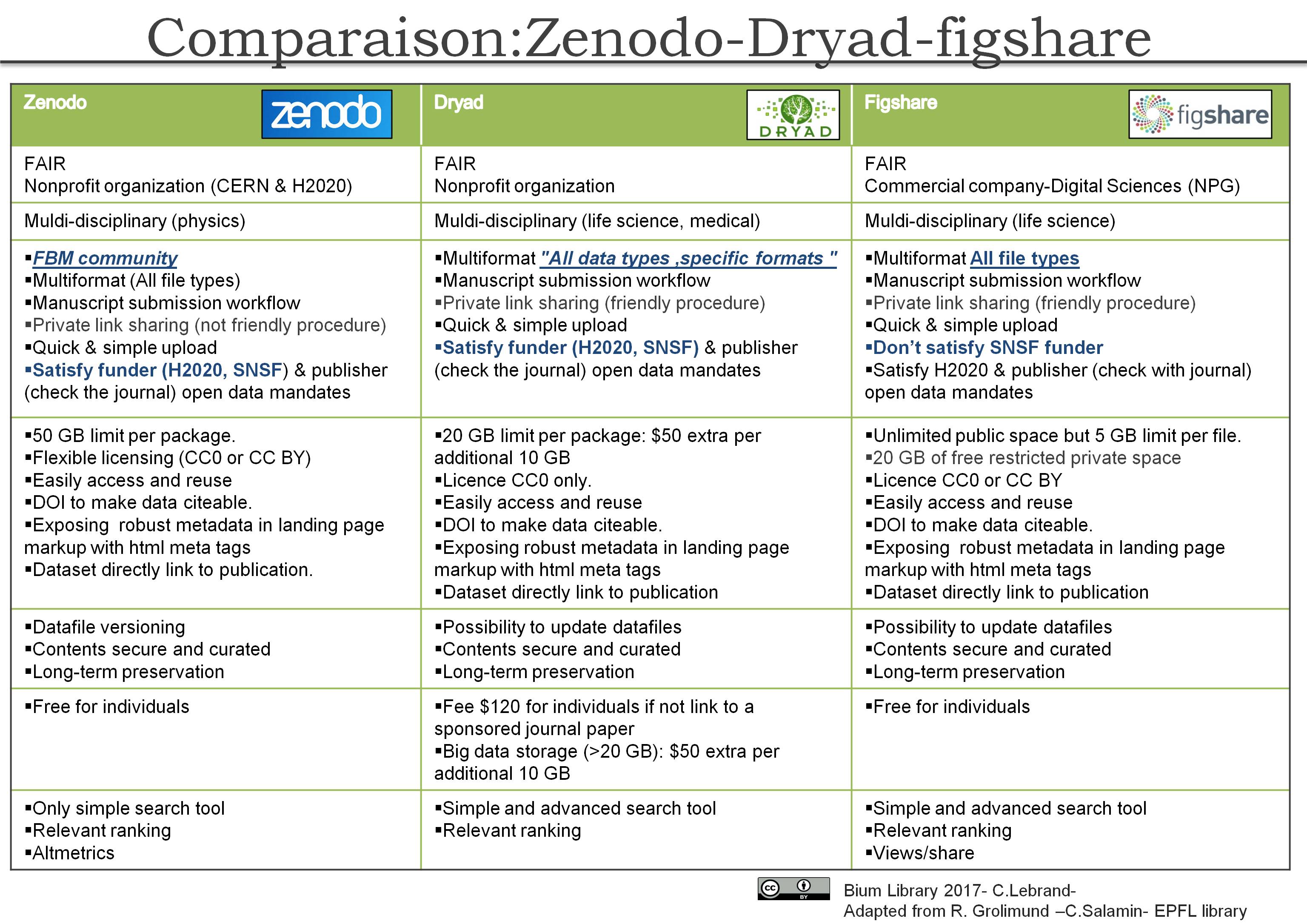
Have a look at our comparison for positive and negative aspects concerning Dryad, Zenodo and figshare.
See also Dataverse comparative review of data repositories
Zenodo

Zenodo is supported by the H2020 programme.
Zenodo repository key caracteristics:
- compatible with the SNSF policy on Open Research Data that expects all its funded researchers to deposit and share their data and metadata onto existing public repositories.
- share research data for free in a wide variety of formats including text, spreadsheets, audio, video, and images across all fields of science
- get credited by making the research data citable (stored data get a DOI to make them easily and uniquely citeable).
- easily access and reuse shared research data
- flexible licensing
- preserve data (research data are are stored safely under the same cloud infrastructure as research data from CERN’s Large Hadron Collider).
- integrate research data into reporting lines for research funded by the European Commission via OpenAIRE.
The BiUM publication management unit strongly recommends to FBM/CHUV researchers to post their supplementary files and key datasets accompanying the publication openly available on the Zenodo-FBM/CHUV community.
Zenodo-FBM/CHUV community.
Services & tools
For help on documenting your data before depositing it on Zenodo contact the BiUM publication management unit. For help on depositing your data on Zenodo FBM/CHU community, have a look at our Zenodo scenarios.
Deposit a dataset on Zenodo
Déposer un logiciel sur Zenodo depuis GitHub
Dryad

Dryad is a nonprofit organization that provides long-term access to its contents at no cost to researchers, educators or students, irrespective of nationality or institutional affiliation. Dryad’s Data Publishing Charges (DPCs) are designed to sustain its core functions by recovering the basic costs of curating and preserving data. New innovations are enabled by research and development grants and by support from donors.
Dryad repository key caracteristics:
- Flexible about data format, while encouraging the use and further development of community standards.
- compatible with the SNSF policy on Open Research Data that expects all its funded researchers to deposit and share their data and metadata onto existing public repositories.
- Only CC0 licensing
- Fits into the manuscript submission workflow of its partner journals, making data submission easy.
- Gives journals the option of making data privately available during peer review and of allowing submitters to set limited-term embargoes post-publication.
- Data are linked both to and from the corresponding publication and, where appropriate, to and from select specialized data repositories (e.g. GenBank).
- Assigns data Digital Object Identifiers (DOIs) to data so that researchers can gain professional credit through data citation.
- Promotes data visibility by allowing content to be indexed, searched and retrieved through interfaces designed for both humans and computers.
- Contents are free to download and have no legal barriers to reuse.
- Contents are curated to ensure the validity of the files and metadata.
- Submitters may update datafiles when corrections or additions are desired, without overwriting the original version linked from the article.
- Long-term preservation … by migrating common file formats when older versions become obsolete, and partnering with DataONE to guarantee access to its contents indefinitely.
Costs to deposit data for individual researchers:
The base DPC per data package is $120. DPCs are collected upon data publication. The submitter is asked to commit to the charge at the time of submission, and is charged if the accompanying publication is accepted, unless the associated journal, has already contracted with Dryad to sponsor the DPC.
To determine whether your DPC will be covered, look up your journal. If there is no payment plan in place, the DPC is $120.
Services & tool
For help on documenting your data before depositing it on Dryad contact the BiUM publication management unit for more information.
figshare

figshare allows users to upload easily any file format to be made visualisable in the browser so that figures, datasets, media, papers, posters, presentations and filesets can be disseminated in a way that the current scholarly publishing model does not allow. It allows you to manage your research in the cloud and control who you share it with or make it publicly available and citable.
figshare si supported by the commercial Mc Millan-NPG group and therefore is not compatible with the SNSF policy on Open Research Data that expects all its funded researchers to deposit and share their data and metadata onto existing public repositories.
Figshare repository key caracteristics:
- Make your data more discoverable and open to all your readers
- Secure hosting and visualization in the browser of all file types
- Authors can easily upload files with no concerns about file size or format
- All data is citable and has a DOI
- Manage and measure the impact of your digital files
- Become the solution for your authors to satisfy funder data mandates
- Host files from 2 – 200Gb
- 20 GB of free private space
- Unlimited public space
- Provide your readers with the full story, allowing them access to the data behind the figures
- Publish your data set using CC BY licence
- Persistent hosting of all data, guaranteed.
- Easy integration with existing author submission processes
Tool
For help on depositing your data on figshare, have a look at our figshare scenario.
Metadata standards
Service
To ensure long-term access and re-use of your data by others, the BiUM publication management unit can help you describe precisely your datasets. Practical courses about these aspects are also provided by our service on a regular basis (check the CHUV calendar).
Metadata (data documentation) are absolutely necessary for a complete understanding of the research data content and to allow other researchers to find and re-use your data.
Many metadata standards are available for particular file formats and disciplines. The BiUM recommends using the Dublin Core Metadata Element Set for describing publications and DataCite Metadata Schema for describing general research data based on European recommendation.
Metadata should be as complete as possible, using the standards and conventions of a discipline, and should be machine readable. Metadata should always accompany a dataset, no matter where it is stored.
Tool
For help on documenting your data before depositing it on data repository, have a look at DataCite Metadata Schema.
In addition, DataCite Metadata Schema for Publication and Citation of Research Data can be used to generate a Readme XML file describing your datasets. The DataCite Metadata Schema for Publication and Citation of Research Data allow data to be understood and reused by other members of the research group and add contextual value to the datasets for future publishing and data sharing. We will generate the Readme XML file automatically using the DataCite Metadata Generator after filing the form requesting intrinsic metadata. The Readme XML file ensures compatibility with international standards and is human as well as machine-readable.
- Mandatory elements will include the file name for the results (field Title)/creators name (field Creator)/affiliation (field creator affiliation)/type of data (field Resource Type).
- Recommended elements will include key words (field Subject)/date of data creation (field Date)/link to electronic notebook (field Related Identifier)/details on the methodology used, analytical and procedural information, definitions of variables, vocabularies and units of measurement (field Description).
- Optional elements will include information on the size / format / version / access /funding.
Documentation, metadata, citation” tutoriel en ligne, Mantra.
Documentation:
- Research data need to be documented at various levels:
- Project level: what the study set out to do, how it contributes new knowledge to the field, what the research questions/hypotheses were, what methodologies were used, what sampling frames were used, what instruments and measures were used, etc. A complete academic thesis normally contains this information in detail, but a published article may not. If a dataset is shared, a detailed technical report will need to be included for the user to understand how the data were collected and processed. You should also provide a sample bibliographic citation to indicate how you would like secondary users of your data to cite it in any publications, etc.
- File or database level: how all the files (or tables in a database) that make up the dataset relate to each other; what format they are in; whether they supercede or are superceded by previous files. A readme.txt file is the classic way of accounting for all the files and folders in a project.
- Variable or item level: the key to understanding research results is knowing exactly how an object of analysis came about. Not just, for example, a variable name at the top of a spreadsheet file, but the full label explaining the meaning of that variable in terms of how it was operationalised.
- Some examples of data documentation are:
- laboratory notebooks & experimental protocols
- questionnaires, codebooks, data dictionaries
- software syntax and output files
- information about equipment settings & instrument calibration
- database schema
- methodology reports
- provenance information about sources of derived or digitised data
Metadata:
- The term metadata is commonly defined as “data about data“, information that describes or contextualises the data.
- The difference between documentation and metadata is that the first is meant to be read by humans and the second implies computer-processing (though metadata may also be human-readable).
- Documentation is sometimes considered a form of metadata, because it is information about data, and when it is very structured it can be. The importance of metadata lies in the potential for machine-to-machine interoperability, providing the user with added functionality, or ‘actionable’ information.
Readme file for data sharing “What is a README file, and how do I make mine as useful as possible?”
https://datadryad.org/pages/readme
A README file is intended to help ensure that your data can be correctly interpreted and reanalyzed by others.
There are two ways to include a README with your Dryad data submission:
- Provide a separate README for each individual data file (view an example).
- Submit one README for the data package as a whole (view an example).
Dryad recommend that a README be a plain text file containing the following:
- for each filename, a short description of what data it includes, optionally describing the relationship to the tables, figures, or sections within the accompanying publication
- for tabular data: definitions of column headings and row labels; data codes (including missing data); and measurement units
- any data processing steps, especially if not described in the publication, that may affect interpretation of results
- a description of what associated datasets are stored elsewhere, if applicable
- whom to contact with questions
- If text formatting is important for your README, PDF format is also acceptable.
DataCite Metadata
The DataCite Metadata Schema for Publication and Citation of Research Data distinguishes between 3 different levels of obligation for the metadata properties:
- Mandatory (M) properties must be provided,
- Recommended (R) properties are optional, but strongly recommended and
- Optional (O) properties are optional and provide richer description.
Table 1 and table 2 list the different items you should document about your dataset based on the 3 different levels of obligation. For more details read the entire document provided by DataCite.
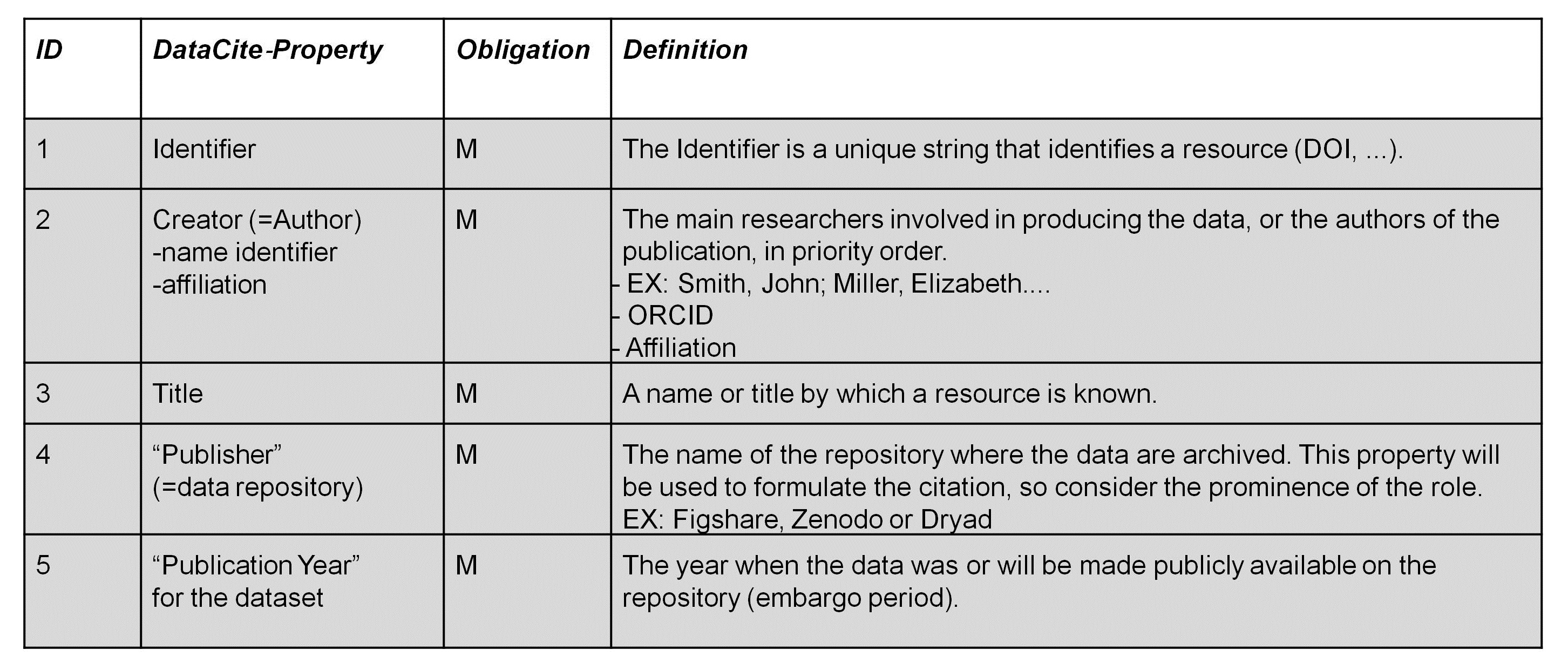
Table 1: DataCite Mandatory Properties
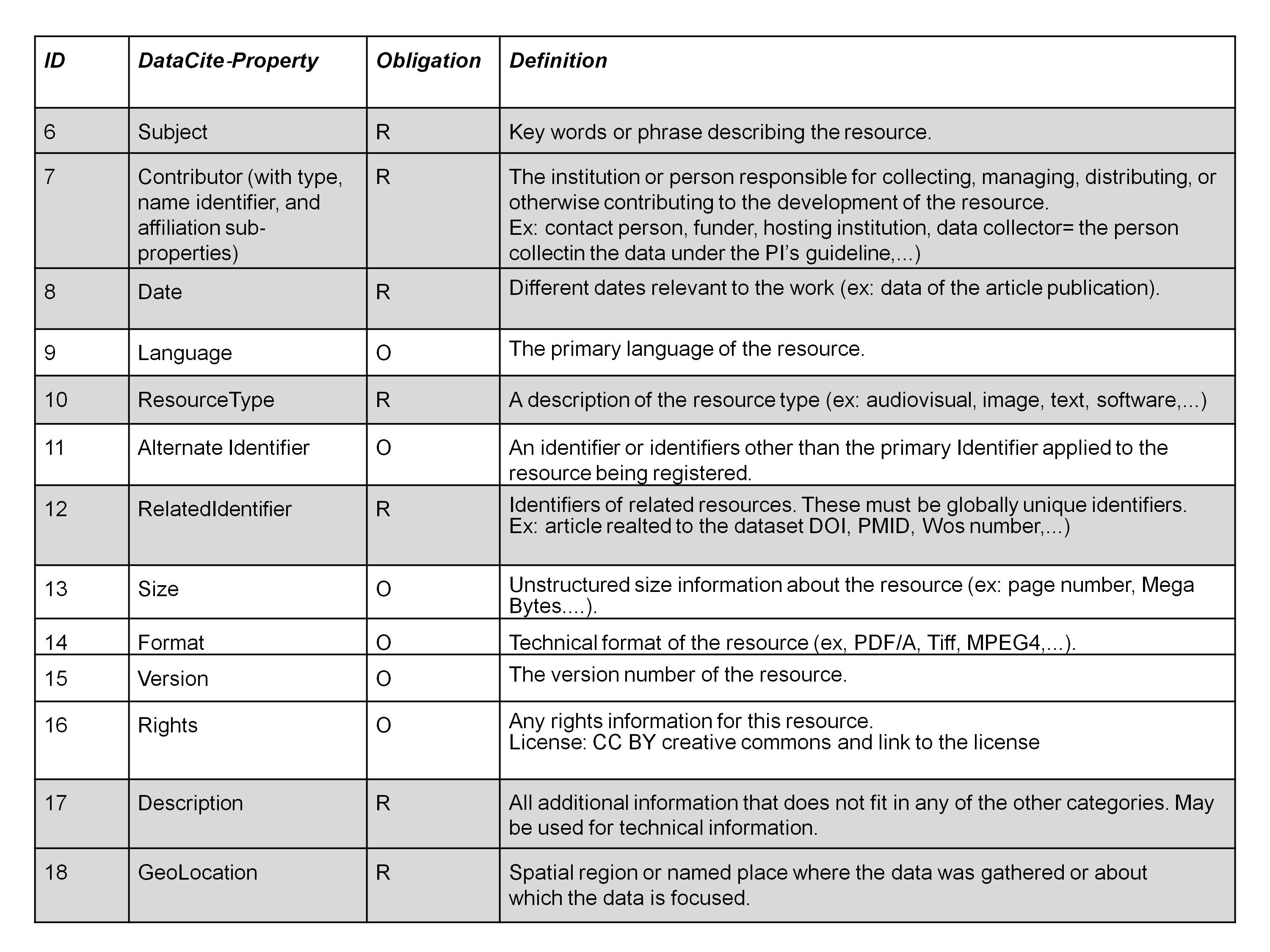
Table 2: DataCite Recommended and Optional Properties
Many academic disciplines have formalized specific metadata standards.
You can consult them on:
Service
To ensure long-term access and usability of your data, the BiUM publication management unit encourages you to deposit documents with the standard preservation file formats most likely to be accessible in the future. We can provide you with guidance on which format to use for long-term preservation of your data. Practical courses concerning these aspects are also provided by our service on a regular basis (check the CHUV calendar).
As technology evolves, it is important to consider which file formats you will use for preserving files in the long run.
File formats most likely to be accessible in the future have the following characteristics:
- Non-proprietary
- Open, documented standard
- Popular format
- Standard representation
- Unencrypted
- Uncompressed
Tool
For help on long-term preservation standards format have a look at FBM Recommended Files format.
Citation for a dataset
Data should be considered legitimate, citable products of research and be given the same importance in the scholarly record as citations of other research objects, such as publications (see Joint Declaration of Data Citation Principles).
Proper citation will help making research data easily accessible and re-usable, while providing researchers due credit for their work. Indeed, since the citation contains the name of the creator, it permits the author to get proper credit. Moreover, the impact of the research dataset can easly be tracked by the unique DOI.
The data citation should be included in the reference list of the article.
- Minimum recommended format
The minimum recommended format for research data citation is as follows:
- Creator (PublicationYear): Title. Publisher. Identifier
Where Publisher is the data archive that holds the data and Identifier is displayed as linkable, permanent URLs.
For example:
« Irino, T; Tada, R (2009): Chemical and mineral compositions of sediments from ODP Site 127‐797. Geological Institute, University of Tokyo. http://dx.doi.org/10.1594/PANGAEA.726855 »
Citation for subject archive entry:
Genbank accession number, available at: http://www.ncbi.nlm.nih.gov.
Data citation templates while using citation software:
- In Endnote use the reference type for dataset.
- In Mendeley or Zotero, use another generic reference type template and fill it with the information for your dataset.
- Tool DataCite website
DataCite website
Access DataCite

Guide « How to Cite Datasets and Link to Publications »
« This guide is very helpful to create links between your academic publications and the underlying datasets, so that anyone viewing the publication will be able to locate the dataset and vice versa. It provides a working knowledge of the issues and challenges involved, and of how current approaches seek to address them. This guide should interest researchers and principal investigators working on data-led research, as well as the data repositories with which they work“.
Research data confidentiality
FBM/CHUV researchers conducting research on human subjects should consult the Commission cantonale d’éthique de la recherche sur l’être humain before planning research data use and sharing.
In case of concern related to clinical trials issues consult the CRC (Centre de Recherche clinique).
| Directeur médical du CRC |
Prof. Marc Froissart
Tél. +41 (0)21 314 61 84 |
| Information |
Intellectual property for datasets
When talking about databases, we first need to distinguish between the structure and the content of a database. The structural elements of a database involving originality will generally be covered by copyright. Concerning the content, individual content items are not copyrightable, while in most juridictions, data collection involving creativity can be copyrightable.
Services
For more information on terms of use and sharing for datasets consult the BiUM publication management unit. In case of concern related to commercial and patenting issues consult the PACTT (Powering Academia-industry Collaborations and Technology Transfer).
Ask us about the use of Open licence tools to make your document freely accessible while protecting your copyrights.
Open licenses for data
Promoting sharing and unlimited use of the data that you have produced yourself is best achieved using explicit licences. For open data it is recommended that you use one of the open compliant licenses marked as suitable for data.
The CC BY license lets others distribute, remix, tweak, and build upon a work, even commercially, as long as they credit the author for the original creation.
Sources of information
EU database directive.
The EU directive provides for both copyright and the sui-generis right though with some restrictions on when you can use the copyright :
« (i) Copyright in the Compilation. … First, it [the DB directive] defines what is meant by a “database”: “a collection of independent works, data or other materials arranged in a systematic or methodical way and individually accessible by electronic or other means.” [DB Dir Art 3] Then it allows copyright in a database (as distinct from its contents), but only on the basis of authorship involving personal intellectual creativity. This is a new limitation, so far as common law countries are concerned, and one which must presage a raising of the standard or originality throughout British Copyright law. Intellectual judgment which is in some sense the author’s own must go either into choosing contents or into the method of arrangement. The selective dictionary will doubtless be a clearer case than the classificatory telephone directory but each may have some hope; the merely comprehensive will be precluded – that is the silliness of the whole construct. »….
« (ii) Database right. In addition there is a separate sui generis right given to the maker of a database (the investing initiator) against extraction or reutilisation of the database. Four essential points may be highlighted:
1. The right applies to databases whether or not their arrangement justifies copyright and whatever position may be regarding copyright in individual items in its contents.
2. The focus upon contents, rather than organisational structure, is intended to give a right where the contents have been wholly or substantially taken out and re-arranged (generally by a computer) so as to provide a quite different organisation to essentially the same material – a re-organisation which would not necessarily amount to infringement of copyright in the original arrangement. …
3. The database has to be the produce of substantial investment. …
4. The right lasts for 15 years from completion of the database, or 15 years from its becoming available to the public during initial period. However, further substantial investment in additions, deletions or alterations starts time running afresh. … »
Swiss and UNIL/CHUV directives
Publish your dataset in data journals
Data papers are articles describing a set of data. This new type of papers are designed to make your data more discoverable, interpretable and reusable. Importantly, these papers are found using well developped classical literatture search databases.
- Scientific Data
Scientific Data is a peer-reviewed open access scientific journal published by the Nature Publishing Group since 2014. Its article-type, the Data Descriptor focuses on descriptions of datasets relevant to the natural sciences. The journal is abstracted and indexed by PubMed.
- GigaScience
GigaScience is an online open-access open-data journal wishing to revolutionize data dissemination, organization, understanding and use. The journal publishes ‘big-data’ studies from the entire spectrum of life and biomedical sciences. To achieve its goals, the journal has a novel publication format: one that links standard manuscript publication with an extensive database that hosts all associated data and provides data analysis tools and cloud-computing resources.
For more information, see the following list of data journals.
Find datasets on Open Data repositories
- How to find a dataset associated with a published article?
Services
The BiUM publication management unit helps all FBM/CHUV researchers finding a repository and datasets. We will give you support to find an adapted repository to deposit your published articles and data underpinning the publication.
Tools
Several aggregator tools have been selected by the BiUM to help researchers finding Open Access repositories where they can retrieve articles and datasets.
Datasets are currently dispersed all around the world on a multitude of repositories. Some authoritative directories such as re3data.org, OAD, OpenAIRE and OpenDOAR help exploring more than 2600 indexed data repositories using search engine for repository contents. Researchers looking for published data related to their research question need to visit each repository individually and manually search for data on each of them.

biosharing is a curated, informative and educational resource on inter-related data standards, databases, and policies in the life, environmental and biomedical sciences
re3data (registrery of research data repositories)

re3data.org website is a directory of more than 1,200 indexed and discoverable data repositories. The recent fusion between re3data service with datacite which provides and assigns permanent Digital Object Identifiers (DOIs) for datasets, will help exploring data repositories and making publications and data more accessible.
OpenDOAR (Directory of Open Access Repositories)

OpenDOAR is an authoritative directory of academic OA repositories developed by SHERPA (Securing a Hybrid Environment for Research Preservation and Access). This service provides a search for repositories or repository contents.
ROARMAP (Registry of Open Access Repository Mandates and Policie)

ROARMAP is a searchable international registry charting the growth of open access mandates and policies adopted by universities, research institutions and research funders that require or request their researchers to provide open access to their peer-reviewed research article output by depositing it in an open access repository.
OAD (Open Access Directory)

OAD is a list of repositories and databases for open data.
The content and the structure of this Web site is licensed under the Creative Commons License (CC BY NC ND Lebrand C.- BiUM library-2016) unless otherwise noted.